- Referenda/
- Small Spender/
- #1825/
[Small Spender] Squidsway Governance Report and Tool
Rejected
Content
AI Summary
Translations
Squidsway Governance Report and Tool
Actionable governance insights, from a rich data chain indexer
The proposal for Squidsway funds two things on an ongoing basis.
The Squidsway tool:
A chain indexer with rich data ingestion modules,
for testing and quickly iterating hypotheses and generating actionable insights about user behaviour.
The Squidsway project:
Publishing governance insight reports roughly every 3 months (and on shorter timescales case-by-case).
Continually adding modules to the tool, to support investigation through the tool, for the purpose of generating insights.
The tool will be open source, for any dev (eg, ecosystem product teams) to use, and future work includes an LLM-based frontend for non-devs to query it.
The project will be funded by the community on an ongoing basis, so will be focused on live, open questions that the community is discussing at any given time. There will be a mechanism for the community to request data on issues of interest.
This proposal funds only the first three months. If the community likes what it sees, then subsequent proposals will fund ongoing work.
This ref, #1825, replaces ref #1823. Nay #1823, Aye #1825 ;D
GOVERNANCE FAILURES ARE A TREASURY ISSUE.
SQUIDSWAY WILL SOLVE THOSE FAILURES FASTER.
I want to improve Polkadot governance because I'm a cypherpunk and I think Polkadot can lead the world, not in just governance of blockchains, but in blockchain-based governance of the offchain world.
Governance is a product on Polkadot, its a field we are leading in, and we should invest in growing the lead we have - make it something to showcase.
But you, dear tokenholder, should fund improving Polkadot governance because
GOVERNANCE FAILURES ARE A TREASURY ISSUE
We are iterating our processes based on assumption, hunches and louder voices, instead of evidence.
That wastes time and costs money.
The alternative to iterating based on vibes is data.
Squidsway is a proposal to collect and compile specific bespoke data, targeted at objectively assessing how OpenGov users respond to everything we do in OpenGov - and to generate insights from these assessments, in order to inform how we continue to iterate OpenGov.
Deliverables
This first proposal is for $8k USDT, to fund 80 (=40+40) hours over around 3 months,
being the development of an MVP, followed by the first half of the validation phase.
At the end of the work funded by this proposal, the tool should consist of:
modules to:
. ingest relevant governance events from chain data
. ingest structured/quantitative offchain data (e.g. from Polkassembly)
. curate data (using queries to assign tags, e.g. "whale", "shrimp")
and
. an indexer capable of reindexing based on these types of data.
At the end of the work funded by this proposal, I expect that the outputs I will report to be sufficient to demonstrate that the tool is functioning - concrete, but probably boring and uncontentious, observations.
Don't worry- the plan is for the insights to become more insightful over time as the tool grows to be able to ingest and compile more awkwardly structured data!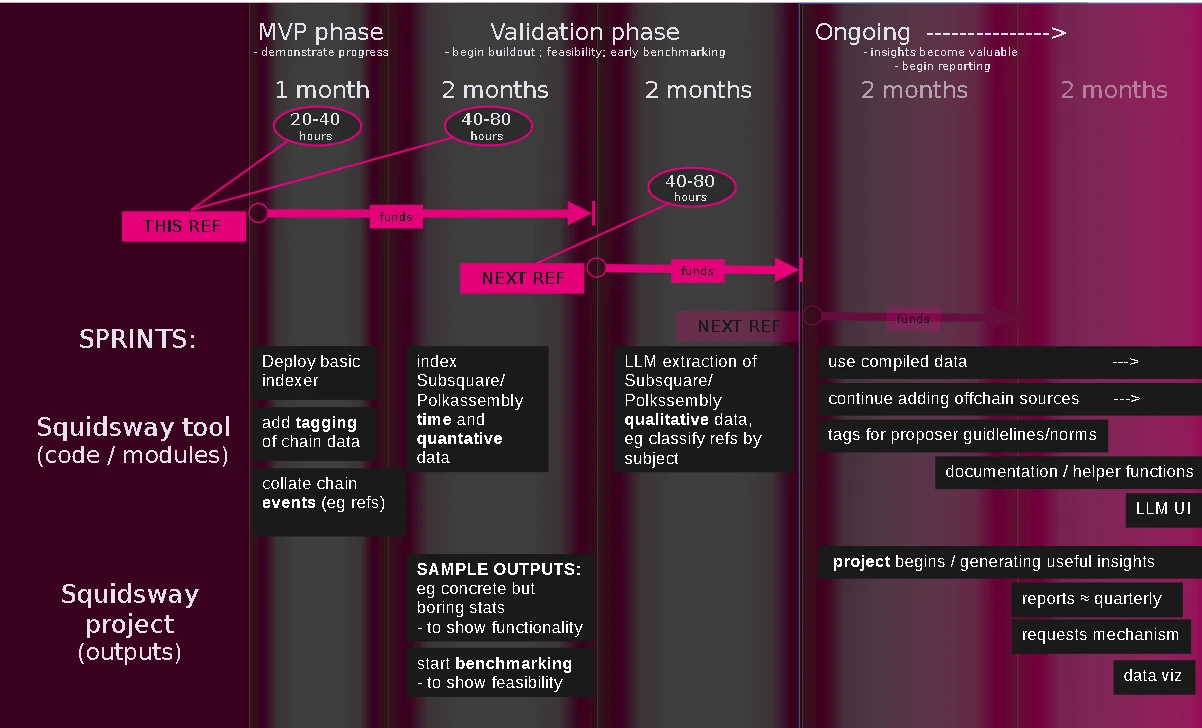
The second proposal would fund the second half of the validation phase.
By the end of that work, I intend that the tool will be ingesting qualitative (natural language) data and outputs would begin to demonstrate what is possible with the tool. I should also have some basic benchmarking to flag up any feasibility questions and potential non-labour costs for the future.
At the end of each funded period, I will report the hours spent on each sprint or other labour.
Overspends in each funding period will be added on to the next proposal for retrospective funding.
Underspends will be subtracted from the next proposal or, in the case of the project winding down (i.e. if a referendum fails), returned to treasury.
Funding
I am proposing to work via sprints, each being 20-80 hours, at $100/hr.
I am proposing to, initially, submit individual treasury referenda to fund upfront around 2 months of work (40-160 hours) each, initially with their own proposals which will be updates to this original proposal.
When the work and delivered outputs settle into a more steady rhythm (i.e. timing, expectations and amount to request become predictable), I plan to switch to the Treasury Guardian model (scheduled funding).
After about a year, the need to code modules to ingest new data sources should have reduced significantly, leaving the compilation of data (ie reindexing and querying) as the largest labour cost (which would also reduce if the LLM frontend becomes popular).
I would hope that, a year after the validation phase, that multiple people in the community will be proficient in using the tool, so that compiling the governance report would be less about the project generating insights and more like curating insights generated by the community using the tool.
Methodology
The methodology is intended to be very, very agile.
The idea of generating insights is to tell us something we didn't know, rather than setting out to prove or disprove a pre-defined set of hypotheses.
Central to that is the ability to, in investigative terms, 'pull on threads' - or, in software terms, to 'rapidly iterate'. This means that the treasury will, for each sprint/for each proposal, be funding something that it does not know what it will be.
This agile way of working is necessary because:
- We need to go where the evidence takes us
- It's likely that many of each of the small technical steps that would make up a milestone can only be identified once a previous step is complete, so identifying and costing out these small technical steps in advance would either lead to wasted labour or force investigations down an inflexible path.
The fact that, in the base case of Squidsway funding referenda, the treasury will be funding something unknown should be mitigated by the ongoing nature of the project, and the fact that each 'milestone' (ie funding period) is a small amount.
Any Questions?
The tool is a backend, not a frontend
How is different from, say, Dune Analytics?
What do we get from these governance insights?
What kind of 'user behaviour' are we trying to encourage?
What are these 'iterations' of OpenGov?
WTF is 'rich data' / 'chain indexer'?
Read the full proposal
Edited
- Squidsway is a project to improve Polkadot's governance.
- It will make a tool that collects data about how people vote and act.
- The tool will help find problems and make governance better.
- It will also create reports every few months to share what is learned.
- The tool will be free for anyone to use and will be open source.
- This first part asks for $8,000 to build a simple version of the tool.
- The goal is to help Polkadot lead in good governance.
Source
Squidsway Governance Report and Tool
Actionable governance insights, from a rich data chain indexer
The proposal for Squidsway funds two things on an ongoing basis.
The Squidsway tool:
A chain indexer with rich data ingestion modules,
for testing and quickly iterating hypotheses and generating actionable insights about user behaviour.
The Squidsway project:
Publishing governance insight reports roughly every 3 months (and on shorter timescales case-by-case).
Continually adding modules to the tool, to support investigation through the tool, for the purpose of generating insights.
The tool will be open source, for any dev (eg, ecosystem product teams) to use, and future work includes an LLM-based frontend for non-devs to query it.
The project will be funded by the community on an ongoing basis, so will be focused on live, open questions that the community is discussing at any given time. There will be a mechanism for the community to request data on issues of interest.
This proposal funds only the first three months. If the community likes what it sees, then subsequent proposals will fund ongoing work.
This ref, #1825, replaces ref #1823. Nay #1823, Aye #1825 ;D
GOVERNANCE FAILURES ARE A TREASURY ISSUE.
SQUIDSWAY WILL SOLVE THOSE FAILURES FASTER.
I want to improve Polkadot governance because I'm a cypherpunk and I think Polkadot can lead the world, not in just governance of blockchains, but in blockchain-based governance of the offchain world.
Governance is a product on Polkadot, its a field we are leading in, and we should invest in growing the lead we have - make it something to showcase.
But you, dear tokenholder, should fund improving Polkadot governance because
GOVERNANCE FAILURES ARE A TREASURY ISSUE
We are iterating our processes based on assumption, hunches and louder voices, instead of evidence.
That wastes time and costs money.
The alternative to iterating based on vibes is data.
Squidsway is a proposal to collect and compile specific bespoke data, targeted at objectively assessing how OpenGov users respond to everything we do in OpenGov - and to generate insights from these assessments, in order to inform how we continue to iterate OpenGov.
Deliverables
This first proposal is for $8k USDT, to fund 80 (=40+40) hours over around 3 months,
being the development of an MVP, followed by the first half of the validation phase.
At the end of the work funded by this proposal, the tool should consist of:
modules to:
. ingest relevant governance events from chain data
. ingest structured/quantitative offchain data (e.g. from Polkassembly)
. curate data (using queries to assign tags, e.g. "whale", "shrimp")
and
. an indexer capable of reindexing based on these types of data.
At the end of the work funded by this proposal, I expect that the outputs I will report to be sufficient to demonstrate that the tool is functioning - concrete, but probably boring and uncontentious, observations.
Don't worry- the plan is for the insights to become more insightful over time as the tool grows to be able to ingest and compile more awkwardly structured data!
The second proposal would fund the second half of the validation phase.
By the end of that work, I intend that the tool will be ingesting qualitative (natural language) data and outputs would begin to demonstrate what is possible with the tool. I should also have some basic benchmarking to flag up any feasibility questions and potential non-labour costs for the future.
At the end of each funded period, I will report the hours spent on each sprint or other labour.
Overspends in each funding period will be added on to the next proposal for retrospective funding.
Underspends will be subtracted from the next proposal or, in the case of the project winding down (i.e. if a referendum fails), returned to treasury.
Funding
I am proposing to work via sprints, each being 20-80 hours, at $100/hr.
I am proposing to, initially, submit individual treasury referenda to fund upfront around 2 months of work (40-160 hours) each, initially with their own proposals which will be updates to this original proposal.
When the work and delivered outputs settle into a more steady rhythm (i.e. timing, expectations and amount to request become predictable), I plan to switch to the Treasury Guardian model (scheduled funding).
After about a year, the need to code modules to ingest new data sources should have reduced significantly, leaving the compilation of data (ie reindexing and querying) as the largest labour cost (which would also reduce if the LLM frontend becomes popular).
I would hope that, a year after the validation phase, that multiple people in the community will be proficient in using the tool, so that compiling the governance report would be less about the project generating insights and more like curating insights generated by the community using the tool.
Methodology
The methodology is intended to be very, very agile.
The idea of generating insights is to tell us something we didn't know, rather than setting out to prove or disprove a pre-defined set of hypotheses.
Central to that is the ability to, in investigative terms, 'pull on threads' - or, in software terms, to 'rapidly iterate'. This means that the treasury will, for each sprint/for each proposal, be funding something that it does not know what it will be.
This agile way of working is necessary because:
- We need to go where the evidence takes us
- It's likely that many of each of the small technical steps that would make up a milestone can only be identified once a previous step is complete, so identifying and costing out these small technical steps in advance would either lead to wasted labour or force investigations down an inflexible path.
The fact that, in the base case of Squidsway funding referenda, the treasury will be funding something unknown should be mitigated by the ongoing nature of the project, and the fact that each 'milestone' (ie funding period) is a small amount.
Any Questions?
The tool is a backend, not a frontend
How is different from, say, Dune Analytics?
What do we get from these governance insights?
What kind of 'user behaviour' are we trying to encourage?
What are these 'iterations' of OpenGov?
WTF is 'rich data' / 'chain indexer'?
Read the full proposal
Edited
Request
8,000USDT
Status
Decision28d
Confirmation
2dAttempts
0
Tally
0%Aye
50.0%Threshold
100%Nay
Aye
≈1.41KDOT
Nay
≈14.5MDOT
- 0.00%
- 0.0%
Threshold
- 0.0%
Support
0.00%≈1.39KDOT
Issuance
≈1.64BDOT
Votes
Nested
Flattened
Actions
Check how referenda works here.
Call
Metadata
Timeline4
Votes Bubble
Curves
Statistics
Timeline
Comments
Request
8,000USDT
Status
Decision28d
Confirmation
2dAttempts
0
Tally
0%Aye
50.0%Threshold
100%Nay
Aye
≈1.41KDOT
Nay
≈14.5MDOT
- 0.00%
- 0.0%
Threshold
- 0.0%
Support
0.00%≈1.39KDOT
Issuance
≈1.64BDOT
Votes
Nested
Flattened
Actions
Check how referenda works here.